안녕하세요, 개발이 필요 없는 게임 서버 뒤끝입니다.
작년부터 뒤끝은 KAIST 인공지능대학원과 인과관계 추론 중 하나인 업리프트 모델링에 대한 연구를 진행했습니다.
그 과정에서 뒤끝을 이용하고 계시는 몇몇 고객사분들의 데이터 제공 및 공개 동의를 받아 해당 데이터로 연구를 시작했고, AAAI 2023에 논문이 채택되는 큰 성과를 얻을 수 있었습니다. (다시 한 번 고객사분들께 감사드립니다.)
상대적으로 다른 AI 분야 보다 연구가 진행되지 않은 인과관계 추론 분야에서, 연구 발전에 기여하고자 해당 데이터셋(Backnd-TS)을 공개하기로 결정했습니다.
- openreview 논문 링크
- 데이터셋 다운로드는 여기에서 가능합니다.
- 영어 버전은 여기에서 확인할 수 있습니다.
- 발표 포스터는 여기에서 확인할 수 있습니다.
Backnd-TS Dataset

Official repository of the paper: Modeling Uplift from Observational Time-Series in Continual Scenarios (Oral presentation, AAAI 2023 Bridge Program for Continual Causality
초록
기계학습에서 인과관계의 중요성이 증가함에 따라, 모델이 분포의 변화에도 견고하도록 정확한 원인기제를 학습할 수 있기를 기대합니다. 기존 벤치마크들이 시각 및 자연어 분야에 집중된 반면, 인과관계 추론 문제에서의 도메인 및 시간적 변화는 충분히 조사되지 않았습니다. 이를 위해 우리는 지속 학습 시나리오에서의 업리프트를 모델링하기 위한 Backnd-TS 데이터셋을 소개합니다. 우리는 CRUD 데이터를 이용해 데이터셋을 구축했으며, 시간적 및 도메인 변화 하에서 지속 학습 테스크들을 제안합니다.
소개
본 데이터셋은 카이스트 인공지능대학원과의 협업을 통해 개발되었습니다. 2023년 1월 기준, 뒤끝은 3,174개의 모바일 게임에 사용되고 있습니다. 누적 유저 수는 6천만 명을 넘어섰으며, 하루에 1억 1천 5백만 건의 트랜잭션이 발생하고 있습니다. 본 데이터셋은 이러한 로그 데이터를 활용하여 유저의 행동을 예측하여, 게임 서비스의 운영을 개선하는 데에 목적이 있습니다.
대부분 인터넷 서비스의 로그 정보는 매일 거대한 규모로 생성되지만, 그 규모에 비해 그 유효성은 미비합니다. 따라서 이러한 로그 데이터는 일반적으로 데이터 웨어하우스에 저장되며, 데이터 과학 및 분석에 사용되는 비율은 매우 적습니다. 이때 분석은 서비스와 회사 수준의 거시적 관점에서 수행되지만, 개별 사용자의 관심사나 예측은 상대적으로 덜 중요합니다. 그러나 이 데이터셋의 관심사는 개별 사용자의 행동을 예측하는 것으로, 사용자 만족도와 서비스 품질을 향상시키는 데에 기여합니다. 또한 기계 학습 및 데이터 마이닝의 관점에서, 데이터셋은 최소한의 전처리를 통해 만들어져 사람에 의한 특징 공학 및 선택에 대한 의존을 줄이고 더 많은 정보를 포함하도록 개발되었습니다.
태스크 설명
태스크는 크게 ID (In-distribution), TS (Temporal Shift), OOD (Out-of-domain)으로 구성되어 있고, 업리프트 모델링에 사용되는 게임은 총 3개(A, B, C)입니다. 이를 정리하면 아래의 표와 같습니다.
| Task | Train set | Valid set | Test set |
|---|---|---|---|
| ID | Game A APR + MAY | Game A APR + MAY (20% split) | – |
| TS | Game A APR + MAY | Game A APR + MAY (20% split) | Game A JUN |
| OOD w/ | Game A APR + MAY & Game B JUN | Game B JUN (20% split) | Game B JUL |
| OOD w/o | Game A APR + MAY | Game A APR + MAY (20% split) | Game C JUL |
- ID는 게임 A의 전체 데이터에서 임의로 추출된 검증 데이터(validation set)에서의 성능을 측정하는 것입니다. 나머지는 훈련 데이터(train set)으로 사용합니다. 훈련 데이터와 검증 데이터가 동일한 게임과 시점에서 수집된 데이터이기 때문에 분포가 동일하다고 가정할 수 있고, 이는 업리프트 모델의 베이스라인 성능 측정을 위해서 사용됩니다.
- TS는 ID에서 훈련된 모델의 성능을 훈련 데이터로부터 한 달 가량 떨어진 시점에서 수집된 평가 데이터(test set)로 성능을 평가합니다. 이는 업리프트 모델이 과거의 데이터로 훈련 시킨 모델을 기반으로 미래 사용자의 행동을 예측한다는 점에서 ID보다 더 현실적인 시나리오입니다. 만약 모델이 시간축에 의한 분포 변화에 견고한 특성들을 배웠다면, TS에서의 성능은 ID와 유사할 것입니다.
- OOD는 위에서 훈련된 모델에서 사용된 것과 다른 게임인 B와 C에서 수집된 평가 데이터(test set)로 성능을 평가합니다. 이는 업리프트 모델이 훈련 데이터와는 다른 게임의 사용자의 행동을 예측한다는 점에서 모델의 더 넓은 범위의 일반화 성능을 평가합니다. OOD는 2개의 세부적인 태스크로 구분됩니다.
- OOD w/: 게임 B의 새로운 학습 데이터가 주어지며, 위 ID에서 훈련한 모델을 새로운 게임에 파인튜닝(fine-tuning)한 후, 성능을 학습 데이터보다 미래 시점의 평가 데이터에서 평가합니다. 이는 도메인이 변동되었을 때 모델의 일반화 성능을 평가합니다.
- OOD w/o: 게임 C에서 수집된 평가 데이터를 사용하여 ID에서 훈련된 모델의 성능을 평가합니다. 마찬가지로 이는 도메인이 변동되었을 때 모델의 일반화 성능을 평가한다는 점에서 동일하지만, ID에서 훈련된 모델에 대한 미세조정(fine-tuning)을 수행하지 않습니다. 만약 모델이 도메인 변동에 견고한 특성들을 배웠다면, OOD w/o에서의 성능은 준수한 수준일 것입니다.
데이터셋 설명 – Dataset Description
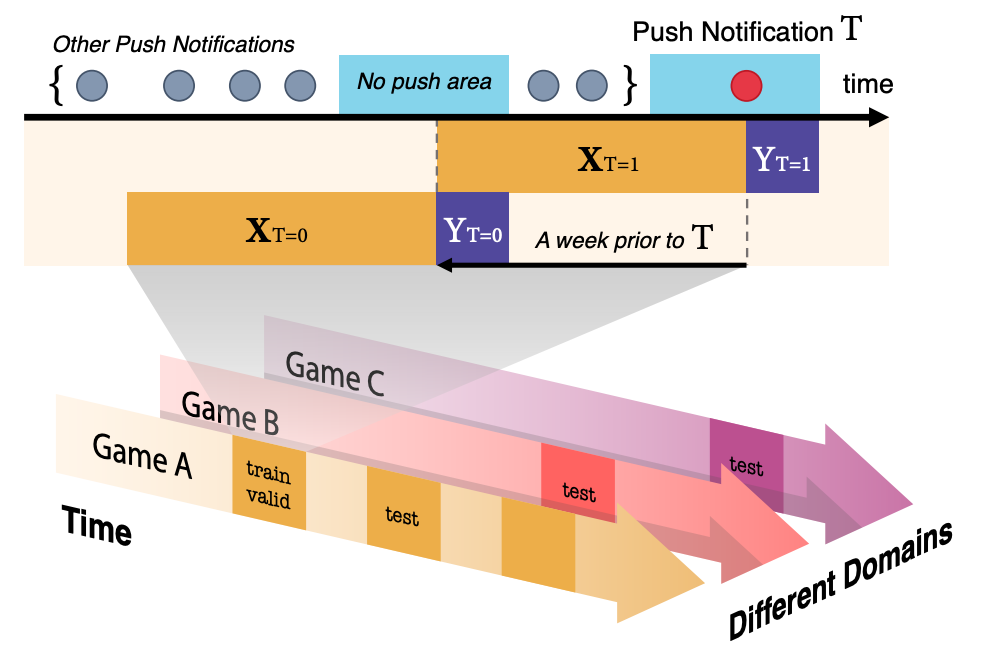
위 그림은 Backnd-TS 데이터셋의 구조 및 태스크를 보여줍니다. 아래의 화살표들은 태스크의 개요를 직관적으로 보여줍니다. 서로 다른 색깔의 화살표는 동일한 서비스 내에서 서로 다른 게임들이 존재한다는 것을 의미하고, 화살표가 시간축으로 나아가는 것은 시간에 따른 분포 변화가 있음을 함의합니다. 업리프트 모델링은 궁극적으로 처치에 대한 미래 사용자의 영향을 예측하는 것이 목표이므로, train 및 valid에 비해 test가 시간적으로 더 뒤에 위치한 것은 이를 반영한 것입니다.
각 데이터는 $(X, t, y)$의 튜플로 존재합니다. 여기서 $X$는 시계열 데이터를 의미하며 $t, y \in { 0, 1 }$은 바이너리 값으로 각각 푸시(처치)를 받은 여부와 푸시를 받은지 {3, 6, 12} 시간 내에 로그인한 여부를 나타냅니다. 논문에서는 3시간을 타겟으로 사용되었지만, 6시간과 12시간도 실험에 사용될 수 있습니다. 이는 시간 간격이 길어질수록 푸시 이외의 원인으로 게임에 접속하는 비율이 증가함에 따라 푸시 자체의 효과는 감소하기 때문에, 다른 푸시의 영향에 관계없이 처치 효과 자체만을 측정하기 위함입니다.
다만 이 데이터는 RCTs(Randomized Controlled Trials, 무작위 배정 임상시험)의 환경에서 수집된 데이터가 아닌 관측 데이터라는 점에 유의해야 합니다. 다시 말해서, 전체 유저를 랜덤하게 두 집단으로 나눈 뒤에 한 집단에는 푸시 메세지를 보내고, 다른 집단에는 그러지 않았을 때 반응(로그인)을 관찰한 데이터가 아닙니다. 게임의 로그 속에서 푸시를 보낸 시점을 기준으로 정확히 1주일 전을 전후로 푸시를 보내지 않았을 때, 이를 통제 집단(control group) 데이터로 사용했습니다. 이를 논문에서는 가짜 통제 집단(pseudo-control group)이라고 칭했습니다. 이를 통해 요일, 시간적 특성 등의 요인이 유저의 로그인 여부에 영향을 받지 않도록 했습니다. 처치(treatment)에 영향을 미친 다른 요인은 존재하지 않고, 통제 집단(control group)과 처치 집단(treatment group)이 동질적이라고 가정했습니다.
베이스라인 – Baselines
베이스라인 모델의 구성은 다음과 같습니다. 백본으로는 Temporal Convolution Network(TCN)[1]이 시계열 정보를 압축하기 위해서 사용되었습니다. RNN 계열 모델이 아닌 TCN이 사용된 이유는 vanilla RNN, LSTM, GRU 모두 긴 시퀀스의 학습이 매우 불안정했기 때문인데, 그 원인으로는 기울기 소실 문제가 꼽힙니다. TCN은 dilated convolution[2] 블록을 11개 쌓아 receptive field가 2,048이 되도록 하였고, 인풋 역시도 마지막 2,048개의 로그만을 사용했습니다. 물론 더 긴 길이의 시퀀스를 이용하기 위해 hierarhical modeling 등 다른 모델링 기법이나 binning과 같은 다른 전처리 기법들을 사용해볼 수 있으나, 본 연구에서는 베이스라인을 제공하는 것이 목적이었으므로 이러한 방법은 사용하지 않았습니다. TCN 레이어를 이용하여 hidden representation인 $z = f(X)$를 얻습니다.
업리프트 모델로는 Dragonnet[3]과 Simanese Nework[4]이 베이스라인으로 사용되었습니다. 공통적으로 TCN 백본의 가장 마지막 레이어의 출력을 입력으로 받아 사용합니다. Dragonnet은 주어진 데이터에서 $\hat y = g(z, t)$를 예측함과 동시에 경향 점수(propensity score)라고 불리는 $\hat t = h(z)$를 예측하게 하는 방식으로 정규화(regularization)을 수행합니다. 이때, 신경망 $g(\cdot)$과 $h(\cdot)$은 초반 가중치를 상당히 공유하는 형태로, 경향 점수 예측에 필요한 특성(feature)만이 인과관계 효과 추론에 필수적이라는 사실을 기반으로 합니다. Simanese Network은 Athey와 Imbens[5]가 제안한 Z 변수 변환의 기댓값이 실제 uplift 값과 같다는 사실을 바탕으로, 이를 회귀 문제(regression problem)으로 풀게 됩니다.
사용 방법 – Usage
데이터셋 로드 – Load Dataset
데이터셋은 torch.utils.data.Dataset을 상속받은 UpliftDataset 클래스로 구현되어 있습니다. 이를 통해 데이터셋을 로드할 수 있습니다.
from dataset.dataset import UpliftDataset
dataset = UpliftDataset(
root: str, # 데이터셋이 저장된 경로. info.json 혹은 info.csv 파일이 존재해야 합니다.
preprocess: Callable=None, # 데이터 전처리 함수. 필수적이지 않습니다.
time_transform: Callable=None, # 시간 데이터 전처리 함수. None일 경우 기본 전처리 함수를 사용합니다.
feature_transform: Callable=None, # 특성 데이터 전처리 함수. None일 경우 기본 전처리 함수를 사용합니다.
target_transform: Callable=None, # 타겟 데이터 전처리 함수. None일 경우 기본 전처리 함수를 사용합니다.
y_idx: int=0, # y 값의 인덱스. 기본값은 0입니다. 0은 3시간, 1은 6시간, 2는 12시간 내의 로그인 여부를 의미합니다.
)
info.csv 혹은 info.json 파일에는 각 시계열에 해당하는 parquet 파일의 이름과 t (treatment, 푸시 메시지 보낸 여부) 및 y (로그인 여부) 값이 포함되어 있습니다.
데이터셋 분할 – Split Dataset
UpliftDataset 클래스 내에 split 메소드를 통해 데이터셋을 분할할 수 있습니다.
train_set, valid_set = dataset.split(
by: str='random', # 분할 방법. 'random', 'user', 'match', 'test' 중 하나를 선택할 수 있습니다.
# by='random'일 경우, train_set과 valid_set를 무작위로 분할합니다.
# by='user'일 경우, train_set과 valid_set를 사용자 단위로 분할합니다.
# by='match'는 구현되어 있지 않습니다.
# by='test'일 경우, train_set과 valid_set를 서로 겹치지 않는 테스트 데이터셋으로 분할합니다.
ratio: float=0.2, # valid_set의 비율. 기본값은 0.2입니다.
random_state: int=42, # random_state. 기본값은 42입니다.
**kwargs,
)
업리프트 모델링 및 인과관계 추론 관련 연구에서 matching은 자주 사용되는 방법론입니다. 그러나 그 방법이 다양하므로 해당 구현은 제공하지 않습니다. by='match'를 사용하면 NotImplementedError가 발생합니다. UpliftDataset 클래스를 상속받은 후1 val_by_match 메소드를 통해 matching을 구현할 수 있습니다.
데이터 로더 – Data Loader
시계열의 특성상 각 데이터 포인트들의 길이가 서로 다릅니다. 따라서 dataset/dataset.py 내의 collate_fn는 기본적인 collate function을 구현하였습니다. collate_fn은 torch.utils.data.DataLoader의 collate_fn 인자로 사용됩니다.
The length of each time series is different. Therefore, collate_fn in dataset/dataset.py implements the basic collate function. collate_fn is used as the collate_fn argument of torch.utils.data.DataLoader.
from dataset.dataset import collate_fn
from torch.utils.data import DataLoader
train_loader = DataLoader(
train_set,
batch_size=32,
shuffle=True,
collate_fn=collate_fn,
)
이때, 기본적으로 collate_fn는 max_length와 pad_on_right라는 인자를 갖습니다. 따라서 해당 인자를 모델에 맞게 수정해서 사용하려면, lambda 함수를 사용해야 합니다.
train_loader = DataLoader(
train_set,
batch_size=32,
shuffle=True,
collate_fn=lambda x: collate_fn(x, max_length=2048, pad_on_right=False),
)
이 결과 collate_fn은 {str: torch.Tensor} 형태의 dictionary를 뱉게 되며, 각 키는 다음과 같습니다.
* timestamp: 시간 정보를 담고 있는 torch.Tensor입니다. torch.Tensor의 shape은 (batch_size, max_length)입니다.
* X: API call의 시퀀스를 담고 있는 torch.Tensor입니다. torch.Tensor의 shape은 (batch_size, max_length)입니다. 전처리 방법에 따라 LongTensor일수도, FloatTensor일수도 있습니다.
* t: treatment를 담고 있는 torch.Tensor입니다. torch.Tensor의 shape은 (batch_size,)입니다.
* y: outcome을 담고 있는 torch.Tensor입니다. torch.Tensor의 shape은 (batch_size,)입니다.
훈련 – Train
아래의 스크립트를 통해 훈련을 진행할 수 있습니다. --help를 통해 사용 가능한 인자를 확인할 수 있습니다. 인자들은 args.py 파일에 정의되어 있습니다.
python train.py --help
베이스라인으로 사용된 모델의 코드는 TS2VEC를 기반으로 작성되어 있습니다.
주요 공지 – Disclaimer
본 데이터셋은 연구용 목적으로 CC BY-NC-SA 4.0 라이선스 하에서 공개되었습니다. 본 데이터셋을 사용하여 발생한 모든 결과에 대한 책임은 사용자에게 있습니다. 본 데이터셋을 사용하여 발생한 결과를 공유하고 싶으신 경우, 아래의 연락처로 연락해주시면 감사하겠습니다.
nannullna@kaist.ac.kr
데이터셋 및 베이스라인에 대한 추가적인 업데이트는 아래의 깃헙 레포지토리를 통해 이루어질 예정입니다.
https://www.github.com/nannullna/ts4uplift
인용 – Citation
본 데이터셋을 사용하신 경우, 아래의 논문을 인용해주시면 감사하겠습니다.
@inproceedings{
kim2023modeling,
title={Modeling Uplift from Observational Time-Series in Continual Scenarios},
author={Sanghyun Kim and Jungwon Choi and NamHee Kim and Jaesung Ryu and Juho Lee},
booktitle={Continual Causality Bridge Program at AAAI23 },
year={2023},
url={https://openreview.net/forum?id=pKyB5wMnTiy}
}
참고 자료 – References
[1] Bai, S.; Kolter, J. Z.; and Koltun, V. (2018). An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv preprint arXiv:1803.01271.
[2] Yu, F.; and Koltun, V. 2015. Multi-scale context aggregation by dilated convolutions. arXiv preprint arXiv:1511.07122.
[3] Shi, C., Blei, D., & Veitch, V. (2019). Adapting neural networks for the estimation of treatment effects. Advances in neural information processing systems, 32.
[4] Mouloud, B., Olivier, G., & Ghaith, K. (2020). Adapting neural networks for uplift models. arXiv preprint arXiv:2011.00041.
[5] Athey, S., & Imbens, G. W. (2015). Machine learning methods for estimating heterogeneous causal effects. stat, 1050(5), 1-26.
2


